Tom Crane,
Digirati, March 2017
This work is licensed under a
Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License
The International Image Interoperability Framework (IIIF, pronounced “triple-eye-eff”) is a set of application programming interfaces (APIs) based on open web standards and defined in specifications derived from shared real world use cases. It is also a community that implements those specifications in software, both server and client. This article provides a non-technical overview of the standards, and the benefits they bring to the sharing of content.
A library or museum catalogue uses a metadata scheme for information such as creator or subject. But we don't need this information to enjoy a library, gallery or museum. We don't need to consult the catalogue. We can go and look at things, and curators can arrange things so as to encourage us to look at them.
The records in the catalogue describe the things in the collection. Browsing or searching the records can be easier than hunting through books on the shelves. We can find the descriptions of books by a particular author, or descriptions of paintings of seascapes. The records comprise the descriptive metadata available for each object. The descriptive metadata records are small and easy to share. Machines understand them. When we understand the metadata scheme in use, we understand what the things are, just from looking at the records.
Image credit: Dr. Marcus Gossler (Own work) CC-BY-SA-3.0, via Wikimedia CommonsThe descriptive scheme provided by metadata is also used in the library to present the real objects to us. Books might be shelved by subject, and then by author. A decision has been made about collecting things together to make it easy for us to find them in a physical space. Conventionally, that decision is driven by a metadata scheme. There is usually some relationship between the arrangement of items on view (and in storage), and the model that the metadata scheme uses to describe the world.
In an exhibtion space, that arrangement may be partly or entirely unconnected to a formal metadata scheme, but there has still been a decision made about how objects relate to each other and how they are aggregated in collections for people to look at or interact with.
The metadata scheme helped decide how objects are collected together and made available to humans, but at that point, something else takes over.
Photograph; the Wellcome Institute Library, 1983 Wellcome L0015799 CC BY 4.0, via Wikimedia CommonsThe arrangement of books on shelves, and the design and conventions of book covers, are part of our human API for interacting with the world.
When we find a particular book in a library or look at a painting in a gallery, we don’t need to consult a metadata standard to understand what the text and images on the book cover or on a gallery label mean. It’s part of our shared cultural understanding of the world. We know the publisher, title and author of this book by looking at the “metadata” on the cover; we can pick it up and read it. If we're looking at a painting or a sculpture, the descriptive metadata might help us understand it better, but we never confuse the description with the object itself.
 Image: author photo
Image: author photo
 From
https://uk.pinterest.com/livingpractice/tilda-swinton/
From
https://uk.pinterest.com/livingpractice/tilda-swinton/
We know how the strings of text presented to us on the gallery label relate to what we can see in front of us. We don't need a guide or a key to interpret the label.
Just as the descriptive semantics in the records influence the presentation of the material in a physical space, we can use the metadata to drive navigation online. On the web, we have the ability to shelve a book in many different places at once, so a descriptive metadata scheme gives us powerful tools for exploration. Descriptive semantics inform the collection of books on shelves, the ink-on-paper of a book cover, the labelling of an exhibit or the information architecture of a web site.
These are all perhaps statements of the obvious. We don’t have to consult catalogue metadata to browse, read or view a physical book or painting, or write an essay about it. The Human Presentation API is our cultural awareness of what book covers and gallery labels mean. Which way up to hold a book, whether to start at the back or the front, how to turn the pages, how to interpret a table of contents and navigate to a chapter, how to use an index. We don't need a guide for this part.
We still have our cultural awareness when looking at a digital surrogate on screen. But the computer needs assistance in presenting that digital surrogate and allowing us to interact with it. The process needs to be assisted by metadata to get the right pixels on the screen in the right place, so that our human cultural awareness can take over again. When viewing things over the web, the machines and software involved need help to let us interact with the object.
For years, institutions have been building and buying image servers, image viewers, page turners, discovery applications, learning environments and annotation tools to make their content accessible to the world, and to let the world interact with it. Many wonderful software tools have been made, and many beautiful websites enjoyed by scholars and the interested public.
A digitisation project gets some funding. Some of that pays for the development of a web site to show that collection. Maybe some work is done to make a nice viewer - a page-turner or other client application to read books, present multiple views of a statue or artwork, or similar. Some projects have made use of deep zoom technologies and formats like Zoomify and Seadragon DZI, and invested in Image Server technology. When the funding for a project finishes, the best that can be hoped for it that it remains online, albeit in its own silo of probably non-interoperable content. Formats and technologies ossify and become obsolete. And even when the technologies are still current, there may have been little consideration of how others might later re-use or consume that content. There may be no interoperability other than that afforded by the web itself, at the level of web pages and images. We need something more formal and specific to convey the complex structure of a digitised book or sequence of images, and the description of a digital object for consumption in a viewer is a problem that has been addressed again and again for project after project. The same use cases reappear with different, incompatible solutions.
For anyone trying to use the accumulated wealth of digitised resources from around the world, whether for research or personal interest, the lack of standardisation has meant that each digitised collection needs to be worked with on its own terms. One institution’s image delivery is not compatible with another's. The same problems are solved over and over again in different silos of non-interoperable content.
While a multitude of different standards and practices are expected and even desirable for descriptive metadata, they do nothing for the content itself. There has been no standardised way of referring to a page of a book, or a sentence in a handwritten letter, from one digitised collection to the next. Descriptive metadata standards don't help us. It is not their job to enable us to refer to parts of the work, down to the tiniest detail - interesting marginalia, a single word on a page - and make statements about those parts in the web of linked data. It is not their job to present content, or share it, or refer to it.
Obviously, a standardised way of describing a digital surrogate would be beneficial. It would mean that content has a better chance of a longer life, it would mean that we could benefit from the software development efforts of others by adopting shared formats. Server software to generate the representations and client software to view it need not be reinvented for every project. It would be good if my digitised books worked in your viewer, and yours worked in my viewer, and we could both have the option of picking off-the-shelf viewers as well as building our own. And much more than that - making our digital surrogates interoperable allows others to reuse them in ways we haven't thought of. It's one thing to make descriptions of objects available for reuse through APIs and catalogue records, but we need a model for describing digital representations of objects and a format for software - viewing tools, annotation clients, web sites - to consume and render the objects and the statements made about them, by us and others. The model needs to be rich enough to accomodate composition of all kinds of web resources to enhance, describe and annotate the objects.
A hypothetical effort at standardisation might go along these lines:
This process seemed to start out really well, and progress was made on the requirements for an interoperable standard. But it started geting complex quite quickly, as all the different ways of describing objects begain to bear down on the emerging model. Questions like "does a painting have an author" don't concern us when we are looking at a painting. We don't need to accomodate that kind of question in our human Presentation API. They only get raised when we're talking about what to put in the catalogue records, when we implement a descriptive scheme. In the above discussion, the participants are sometimes talking about the actual objects, and sometimes talking about descriptive metadata about the objects.

The IIIF Presentation API provides:
This doesn't mean that the descriptive metadata has no place in a digital object delivered by the Presentation API. It's important that the object is accompanied by useful information, and links to other descriptions of the object. The Presentation API takes great care to ensure that you can accompany your digital objects with rich human-readable descriptions, with support for multiple languages, so that viewers can display that important contextual information to users. It also provides an explicit mechanism for linking to one or more semantic descriptions of the object depicted, as well as related human-readable resources. There's quite a bit of descriptive metadata being presented here:
 Llyfrgell Genedlaethol Cymru – The National Library of Wales
View on site
Llyfrgell Genedlaethol Cymru – The National Library of Wales
View on site
For the Presentation API, the meaning of any accompanying descriptive metadata for display in a viewer is irrelevant. The API's job is to get the content of the work - the pages of the book, the painting - to a point where a human can interact with it in a logical way. To view it, read it, annotate it, mix it up with other things if they want. A IIIF client can also display any accompanying metadata included as multilingual pairs of labels and values. But that's as far as it goes, it needs no definition or scheme for what that metadata means. It is outside of the scope of the Presentation API. In the screen shot above, the user can view important semantic metadata - but the Presentation API is just a conduit for that text. In the Presentation API, those strings have no semantic significance. They are not defined in the specification. A client of the API should just render them. If you want to know what they mean, look at the link to descriptive metadata that a publisher of IIIF resources provides.
This means that the Presentation API is not a new metadata standard to describe your objects. It is not an alternative to or replacement for any existing descriptive metadata standards, because it has a different function. The many rich and various ways in which different communities describe objects are diverse for good reason. The models a community or an individual institution adopt to describe the meaning of its objects in the world, from cataloguing schemes to APIs, benefit from shared vocabularies and common practice within large communities, but attempts at complete standardisation fail and are not even desirable. The models, standards and APIs an institution adopts for description are an expression of its view of the world. However, while it is not reasonable or desirable that everyone describes their objects the same way semantically, it is desirable that an insitution presents its objects via a common standard. Many descriptive standards, one Presentation standard - for the same reason that it is sensible to make your web pages compatible with most web browsers.
This does not mean that the user experience driven by the Presentation API has to be standard as well; far from it. IIIF is not about standardising the user experience. An object described by the Presentation API could be rendered by a conventional bookreader style viewer, loaded into a scholarly workbench application for annotation, displayed as an explosion of thumbnails, projected into a virtual space, rendered as minimalist web pages, remixed into multimedia presentations, worked into online exhibitions, reused in physical gallery space or turned into games and interactive experiences. The Presentation API model encourages creative re-use of the content, and to this end ensures it stays separate from the descriptive metadata. A Presentation API resource is portable, reusable and interoperable. If you have a digitised resource, you provide a Presentation API resource and a semantic description of the object, and the two link to each other.
How does the Presentation API work?
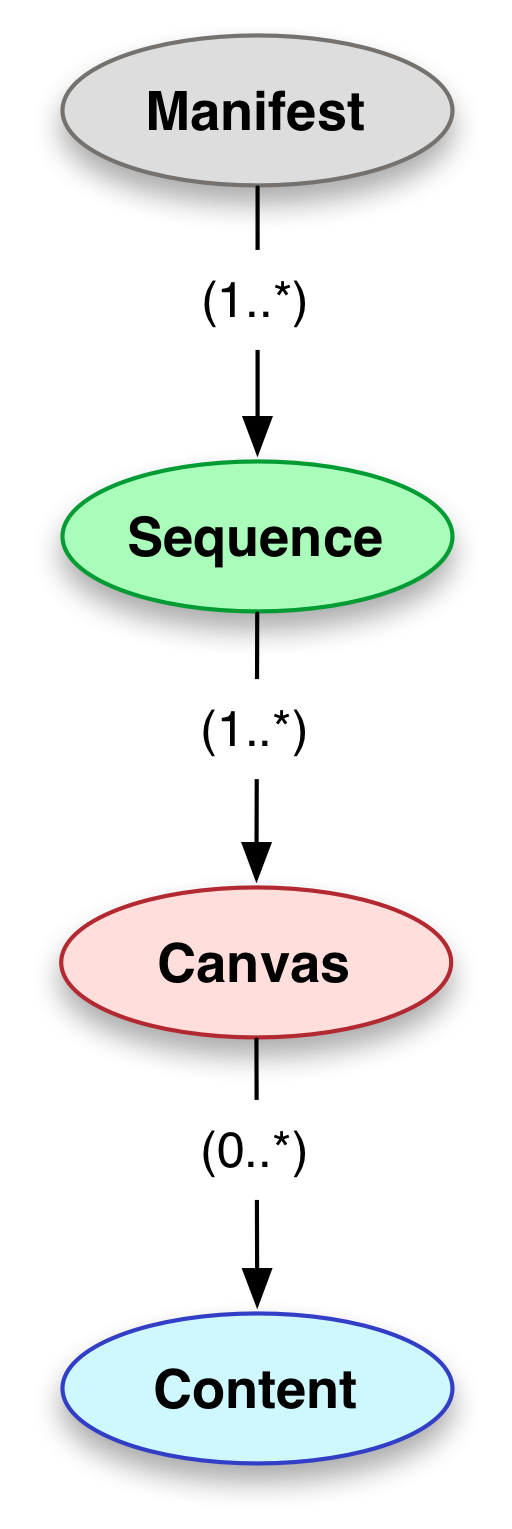
The Presentation API describes “just enough metadata to drive a remote viewing experience”. This metadata is a IIIF Manifest. The Manifest represents the thing. A book. A painting. A film. A sculpture. An opera. A long-playing record. A manuscript. A map. An aural history field recording. A videocassette of a public information film. A laboratory notebook. A diary. All of these things would be represented by a IIIF Manifest. You publish IIIF manifests for each of your objects.
A manifest is what a IIIF viewer loads to display the object. A manifest could be used to generate a web page for the object. A manifest could be loaded into an annotation tool, or a IIIF editing environment to be used as source material in the creation of a new manifest.
If the object the manifest represents is a photograph, there might only be one conceptually distinct view of it that we wish to convey via the Presentation API, to end up on a user's screen. For many objects there is more than one view. Even for a painting, it might be important to include the back of the canvas frame. And for books, manuscripts and much archive material, each page, leaf, folio or sheet is one or two separate views - in its normal state we can't look at all of them at once, the model conveys them as a sequence of distinct views. Depending on how the book has been captured and how we want to model it, we might have one view per page, or one view per double page spread, and extra views for inserts or supplementary material.
These views are represented by Canvases. A Manifest contains one or more Sequences of Canvases. A canvas is not the same as an image. The canvas is an abstraction, a virtual container for content. It's analogous to a PowerPoint slide; an initially empty container, onto which we "paint" content. If we want to provide a sequence of images to a book reading application, or for viewing paintings, the concept of a canvas may seem like an extra layer of complexity. It's not much more complicated to do it this way, but it is much more flexible and powerful.
The canvas is the abstract space; we provide an image to paint the canvas
The Canvas keeps the content separate from the conceptual model of the page of the book, or the painting, or the movie. The content can be images, blocks of text, video, links to other resources, and the content can be positioned precisely on the canvas. By including a Canvas in a Manifest, you provide a space on which you and others can annotate content. For image-based content the PowerPoint analogy is clear: the Canvas is a 2D rectangular space with an aspect ratio. The height and width properties of a canvas define the aspect ratio and provide a simple coordinate space. This coordinate space allows the creator of the manifest to associate whole or parts of content with whole or parts of canvases, and for anyone else to make their own annotations in that space.
This means that you can provide more than one representation of a view. You might have a painting photographed in natural light and in X-ray. You might have a manuscript that was captured to microfilm, and your initial presentation of the material uses images derived from the microfilm. Later, you go back and photograph some of the folios at high resolution, maybe those with illuminations. You can update the content associated with a Canvas without having to retract the canvas and the other content you might already have associated with it.
You may have a manuscript represented as a sequence of Canvases, but for some of those Canvases you have no image at all - the page was known to exist, but is now lost. You may still have text content associated with the Canvas - transcriptions from a copy, commentary, or other notes. The fact that for this particular folio you have no photographic representation doesn't stop you modelling it in the Manifest and associating content with it - just not an image in this case.
All association of content with a canvas is done by annotation. The IIIF Presentation API is built on the Open Annotation standard, which has now become the W3C Web Annotation Data Model. At its simplest, the Web Annotation Data Model is a formalised way of linking resources together:
An annotation is considered to be a set of connected resources, typically including a body and target, and conveys that the body is related to the target. The exact nature of this relationship changes according to the intention of the annotation, but the body is most frequently somehow "about" the target. This perspective results in a basic model with three parts, depicted below. The full model supports additional functionality, enabling content to be embedded within the annotation, selecting arbitrary segments of resources, choosing the appropriate representation of a resource and providing styling hints to help clients render the annotation appropriately.
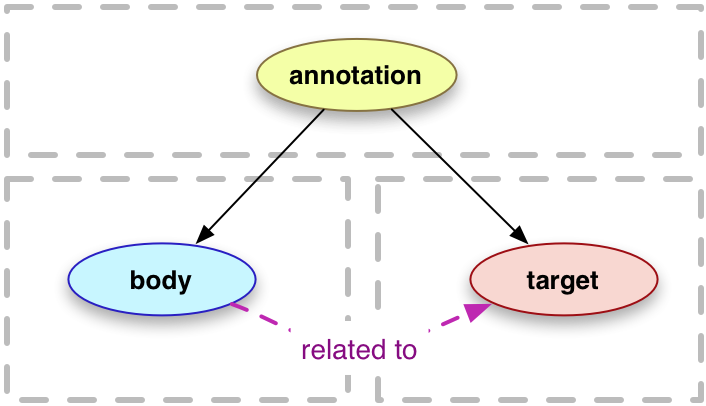
A simple annotation might be an association between a page of a manuscript and an article about that page elsewhere on the web. Or, in the context of a bookreader or viewer, it might be a comment on or transcription of a particular part of the page, or the whole page. This notion of annotations as commentary or transcriptions is familiar:

But in IIIF, the image itself is one just of the pieces of content annotating the abstract canvas. There may be multiple images, there may be no images at all. This diagram shows that all the content a user ever sees rendered by a viewer - images, text and other content - is associated with the virtual space of the canvas via the mechanism of annotation.
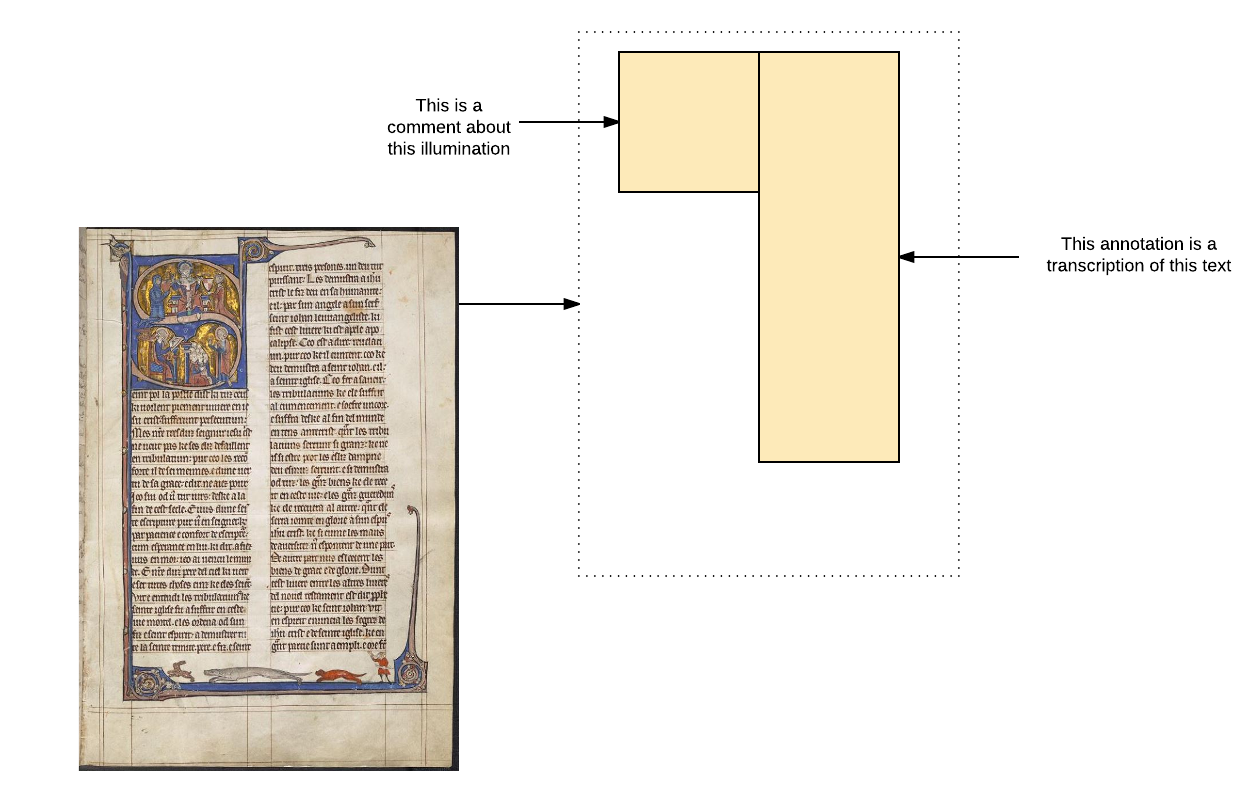
IIIF distinguishes between annotations that are for painting on to the canvas - images, transcriptions - and other annotations, that don't necessarily make sense rendered directly onto the virtual space. For example, commentary might be rendered alongside the image in a viewer, not superimposed on top of it, but transcription could be superimposed directly in a layer that can be toggled on and off:
![]() Wellcome Library,
Public domain
Wellcome Library,
Public domain
When you publish a manifest, you publish a sequence of one or more canvases that are almost always accompanied by one or more image annotations - usually just one. For a digitised book, the manifest that represents it comprises a sequence of canvases, with image annotations:

Although in this initial state each canvas is accompanied in the manifest by just one image annotation, the stage is set for you and others to add more annotations in future. When you add annotations, you might publish them in your manifest alongside the image annotations. When other people annotate your content, they can't do this directly because they can't edit your manifest. But they can still create annotations using the identity and coordinate system you have established for your canvas by your act of publishing it in a manifest. This allows me to make annotations on your content for my own private use, or for me to publish them independently and combine them with your Manifest and its canvases in my own presentation of your material, or even for you to accept my annotations back and incorporate them into your published content.
The canvas establishes a stage in which the simplest case - one image per canvas - is straightforward, but more complex cases, more complex and interesting associations of content, follow naturally. Suppose a manuscript folio that once looked like this:
 Bodleian Libraries
Bodleian Libraries
...was torn up and its various parts scattered. Today, we have images of three surviving parts:


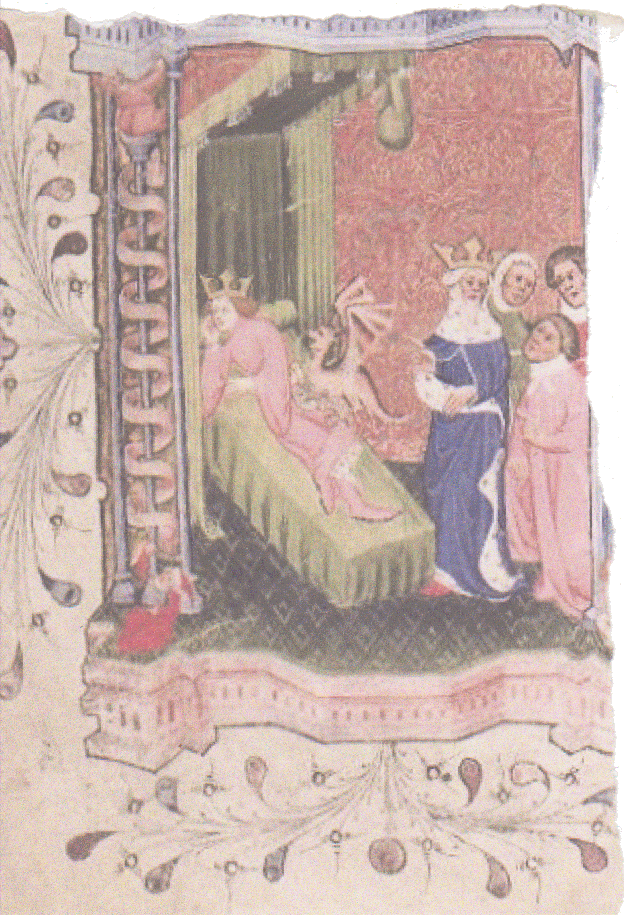
We can include a canvas for this missing leaf, and annotate the three parts we do have onto it, as well as providing some commentary about this missing piece:
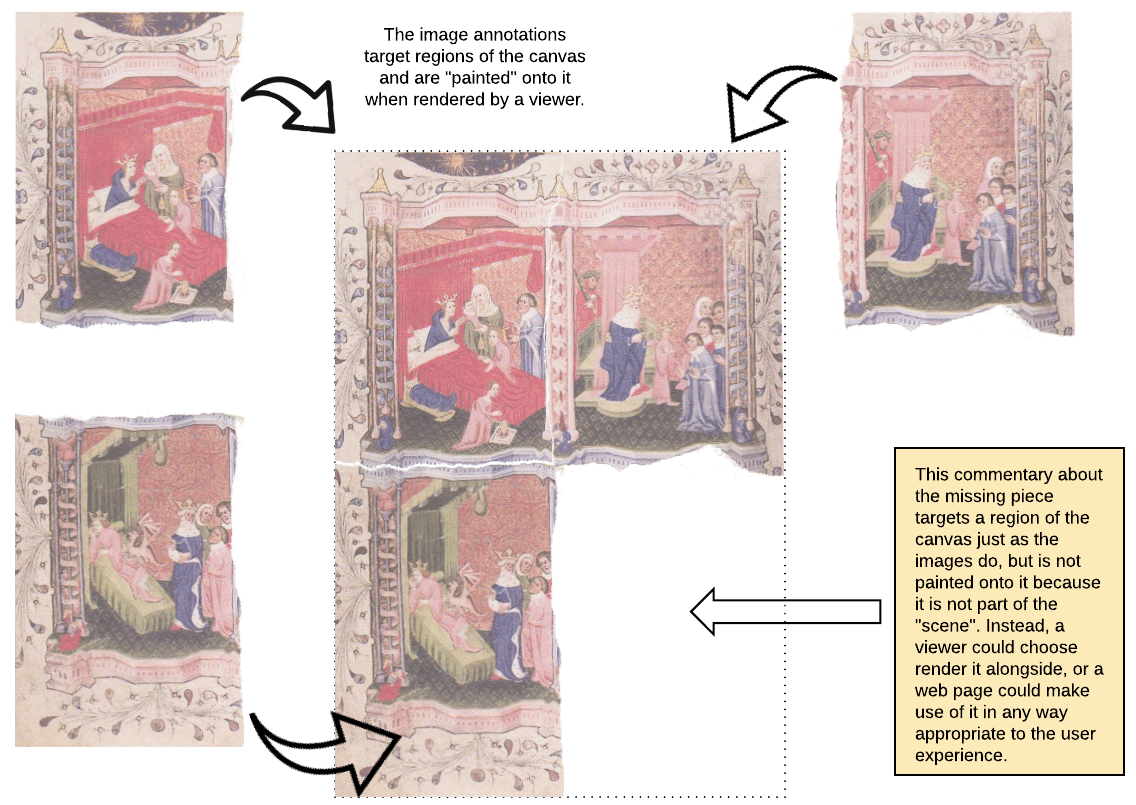
Again, the similarity between this and a PowerPoint slide is noticeable. But unlike a Powerpoint slide, the Manifest, the Canvas and all the annotations of content onto it, are interoperable, and part of the web of linked data. We and anyone else can make statements about them, and add to the statements about them, in the web of linked data. And we publish all this information in easy to consume, interopeable API for ourselves and others to view, interact with, and build new interesting things from.
The IIIF Presentation API isn't just for images. So far we have looked at 2D canvases. The current IIIF Presentation API has supported 2D canvases right from the start. While we can annotate time-based media (audio and video) onto a 2D Canvas in space, in exactly the same way we position images and text onto the canvas using the coordinate system, the current published specification doesn't allow us to annotate images, text, video, audio and other content onto the canvas at a particular point in time, because a Canvas has no duration, no concept of a time dimension to accompany the width and height. If we add a time dimension, it allows us to annotate in both space and time:
 Demonstration of time on a canvas; click to open in new window
Demonstration of time on a canvas; click to open in new window
And also, we can have a Canvas that has only a duration, no width or height - onto which we could annotate audio tracks. The same model accommodates this. In the future, the model may also accommodate 3D or 3D time-based media - but the focus for this year is to make the model work well for AV, just as it does for image and text content.
So far, we have looked at annotating images onto canvases. A manifest contains a sequence of one or more canvases, each of which might have an image and possibly additional content - more images, text annotations, commentary, transcriptions and so on. While single static images are enough to drive a viewing experience, for many objects of cultural heritage having just one image representation available is not very flexible. Typically manuscripts, artworks, maps and to some extent books and archive material are digitised at a very high resolution. We need access to that high resolution to view the detail in an image, but requiring our clients to load multi-mega- or even giga-pixel images just to look at book pages is unreasonable. We need to have a variety of sizes available for different purposes. And ideally, we can choose the regions and sizes we want to use from the image dynamically.
The Image API specifies a syntax for web requests that lets us ask for images at different sizes and in different formats and qualities. Each image endpoint is a web service that returns new derivative images. We can ask for the full image, or regions of the image. We can rotate, scale, distort, crop and mirror the whole image, or parts of the image.

If you provide a IIIF Image API endpoint, you are providing a service that viewers can call to get images. This might be a single static image - you could use the image service to link to an image that’s just the right size for your blog post, using appropriate values in the URL as in the examples above and avoid having to make any new derivatives yourself. This use of the Image API works with any browser that supports images.
Or it might be more complex - a deep zoom viewer works by making many requests for small regions of the image, known as tiles. In the following images, we see an exploded view of the tiles the client is requesting from the Image API. It is asking for small square regions at a particular size and zoom level. Just as you don’t need to load the whole world into Google Maps to view your neighbourhood at street level detail, a deep zoom client doesn’t need to load an enormous image for you to view a particular part of it at the highest resolution. IIIF enables images of Gigapixel size to be viewed in great detail while keeping bandwidth use to the minimum, because the server is able to return small, fast tiles from which the viewer can compose the scene.

You can experiment with tiles using this tool, which shows the tiles a deep zoom viewer would request.
if you have a IIIF Image API endpoint available for each of your images, you have flexibility for how you and others use your image resources. You could, for example, have a static image that turns into a deep zoom image when clicked. Although the image below is a regular image tag that works in all browsers, there is some JavaScript enhancement that turns it into a deep zoom image when clicked. In this case it uses the OpenSeadragon library which is used for deep zoom by viewers such as the Universal Viewer and Mirador:

Click to zoom
Wellcome Library,
Wellcome Library no. 18946i
This technique can be extended to build the simplest of manifest viewers:









Another use of an image server is for generating responsive images without having to create multiple derivatives in an image editing application. The following is a contrived example:
<picture>
<!-- see https://tomcrane.github.io/iiif-img-tag/ -->
<source media="(min-width: 1600px)" srcset="https://dlcs.io/.../120,850,2100,2000/1600,/0/default.jpg">
<source media="(min-width: 700px)" srcset="https://dlcs.io/.../250,850,1950,2000/1000,/0/default.jpg">
<source media="(min-width: 400px)" srcset="https://dlcs.io/.../250,850,900,1000/500,/0/default.jpg">
<img alt="example image" src="https://dlcs.io/.../250,850,900,1000/320,/0/default.jpg">
</picture>
We have seen how images are annotated onto the abstract canvas space, along with other content. The manuscript example showed how a whole image can annotate part of the canvas, but the reverse is also possible - part of an image annotating the whole canvas, or part of an image annotating part of canvas. This might be required when your source image detail that you don't want on the canvas. Here's the image in the repository:
 Bodleian Libraries
Bodleian Libraries
In the viewer we want it to look like this:

Rather than modifying the source image, which contains valuable information, we create an annotation that associates part of the source image with the canvas, rather than all of it:

We haven't modified anything, just used the annotation model to get the results required. The body of the annotation is not a plain image, but a resource that defines a selected region from that image.
Another scenario in where we want to offer a choice between two or more images annotating the same canvas. In the following examples, we have two images of the painting - natural light and X-ray. If we annotated the two images onto the canvas directly, we'd be saying that we want all the images painted onto the canvas. For the torn-up manuscript earlier this was what we wanted, because we want to see them all at the same time and they target different parts of the canvas. For this scenario we can't do that, because one would hide the other (they both target the full extent of the canvas). Instead, we wrap the two images inside a "Choice" annotation, and then annotate that onto the canvas. This conveys to the user interface that it should offer the user means of selecting the images.

Here are some user interface treatments of that choice:
The
iiif.io web site is the place to go for the API specifications and news about the community, and how to get involved.
There is also the
awesome-iiif list, a community-maintained collection of useful/fun/curious IIIF-related writing, software and implementations.
More Digirati updates
{kind=link}
{kind=link}